|
About: I'm a Research Scientist working with the Nextcam team at Adobe on computational photography applications. I received my Ph.D. from Princeton University, where I was part of the Princeton Computational Imaging Lab advised by Professor Felix Heide, and was supported by the NSF Graduate Research Fellowship. I earned my bachelor's degree in electrical engineering and computer science from UC Berkeley. Contact: cout << "contact" << "@" << "ilyac.info" Professional: CV / Google Scholar / Github / LinkedIn / bsky Unprofessional: My Photography / Quotes |


|

|
I'm interested in
Over the course of my research I've written a number of
|


|
Jan Philipp Schneider, Pratik Singh Bisht, NeurIPS, 2025 (Spotlight) Neural Atlas Graphs are a hybrid 2.5D representation for high-resolution, editable dynamic scenes. They model a scene as a graph of moving planes in 3D, each equipped with a view-dependent neural atlas. This structure supports both 2D appearance editing and 3D re-ordering of scene elements, enabling rendering counterfactual scenarios with new backgrounds and modified object appearance. |
|
Neural Atlas Graphs are a hybrid 2.5D representation for high-resolution, editable dynamic scenes. They model a scene as a graph of moving planes in 3D, each equipped with a view-dependent neural atlas. This structure supports both 2D appearance editing and 3D re-ordering of scene elements, enabling rendering counterfactual scenarios with new backgrounds and modified object appearance. |
|


|
My PhD Dissertation, Princeton University, 2025
|
|
|
|


|
SIGGRAPH Asia, 2024 We design a spherical neural light field model for implicit panoramic image stitching and re-rendering, capable of handling depth parallax, view-dependent lighting, and scene motion. Our compact model decomposes the scene into view-dependent ray offset and color components, and with no volume sampling achieves real-time 1080p rendering. |
|
We design a spherical neural light field model for implicit panoramic image stitching and re-rendering, capable of handling depth parallax, view-dependent lighting, and scene motion. Our compact model decomposes the scene into view-dependent ray offset and color components, and with no volume sampling achieves real-time 1080p rendering. |
|


|
Zheng Shi*, SIGGRAPH, 2024 Split-aperture 2-in-1 computational cameras encode half the aperture with a diffractive optical element to simultaneously capture optically coded and conventional images in a single device. Using a dual-pixel sensor, our camera separates the wavefronts, retaining high-frequency content and enabling single-shot high-dynamic-range, hyperspectral, and depth imaging. |
|
Split-aperture 2-in-1 computational cameras encode half the aperture with a diffractive optical element to simultaneously capture optically coded and conventional images in a single device. Using a dual-pixel sensor, our camera separates the wavefronts, retaining high-frequency content and enabling single-shot high-dynamic-range, hyperspectral, and depth imaging. |
|


|
CVPR, 2024 We propose neural spline fields, coordinate networks trained to map input 2D points to vectors of spline control points, as a versatile representation of pixel motion during burst photography. This flow model can fuse images during test-time optimization using just photometric loss, without regularization. Layering these representations, we can separate effects such as occlusions, reflections, shadows and more. |
|
We propose neural spline fields, coordinate networks trained to map input 2D points to vectors of spline control points, as a versatile representation of pixel motion during burst photography. This flow model can fuse images during test-time optimization using just photometric loss, without regularization. Layering these representations, we can separate effects such as occlusions, reflections, shadows and more. |
|


|
CVPR, 2023 In a “long-burst”, forty-two 12-megapixel RAW frames captured in a two-second sequence, there is enough parallax information from natural hand tremor alone to recover high-quality scene depth. We fit a neural RGB-D model directly to this long-burst data to recover depth and camera motion with no LiDAR, no external pose estimates, and no disjoint preprocessing steps. |
|
In a “long-burst”, forty-two 12-megapixel RAW frames captured in a two-second sequence, there is enough parallax information from natural hand tremor alone to recover high-quality scene depth. We fit a neural RGB-D model directly to this long-burst data to recover depth and camera motion with no LiDAR, no external pose estimates, and no disjoint preprocessing steps. |
|


|
Gene Chou, NeurIPS, 2022 (Featured) Signed distance fields (SDFs) can be a compact and convenient way of representing 3D objects, but state-of-the-art learned methods for SDF estimation struggle to fit more than a few shapes at a time. This work presents a two stage semi-supervised meta-learning approach that learns generic shape priors to reconstruct over a hundred unseen object classes. |
|
Signed distance fields (SDFs) can be a compact and convenient way of representing 3D objects, but state-of-the-art learned methods for SDF estimation struggle to fit more than a few shapes at a time. This work presents a two stage semi-supervised meta-learning approach that learns generic shape priors to reconstruct over a hundred unseen object classes. |
|


|
Seung-Hwan Baek, SIGGRAPH, 2022 Modern AMCW time-of-flight (ToF) cameras are limited to modulation frequencies of several hundred MHz by silicon absorption limits. In this work we leverage electro-optic modulators to build the first free-space GHz ToF imager. To solve high-frequency phase ambiguities we alongside introduce a segmentation-inspired neural phase unwrapping network. |
|
Modern AMCW time-of-flight (ToF) cameras are limited to modulation frequencies of several hundred MHz by silicon absorption limits. In this work we leverage electro-optic modulators to build the first free-space GHz ToF imager. To solve high-frequency phase ambiguities we alongside introduce a segmentation-inspired neural phase unwrapping network. |
|
|
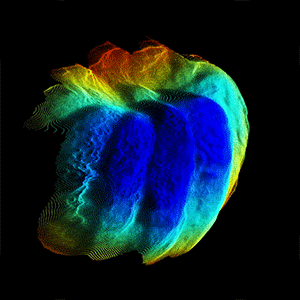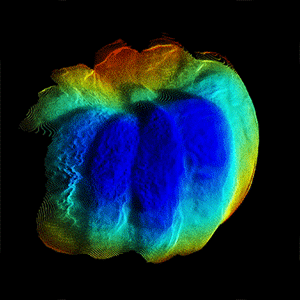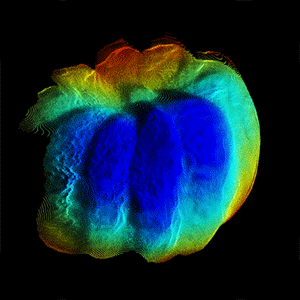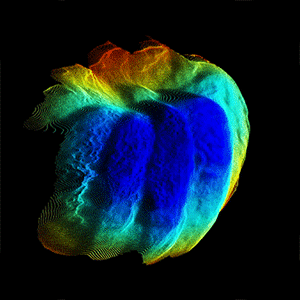
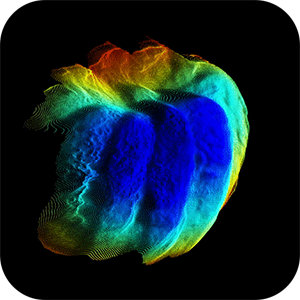
CVPR, 2022 (Oral) Modern smartphones can stream multi-megapixel RGB images, high-quality 3D pose information, and low-resolution depth estimates at 60Hz. In tandem, the natural shake of a phone photographer's hand provides us with dense micro-baseline parallax depth cues during viewfinding. This work explores how we can combine these data streams to get a high-fidelity depth map from a single snapshot. |
|
Modern smartphones can stream multi-megapixel RGB images, high-quality 3D pose information, and low-resolution depth estimates at 60Hz. In tandem, the natural shake of a phone photographer's hand provides us with dense micro-baseline parallax depth cues during viewfinding. This work explores how we can combine these data streams to get a high-fidelity depth map from a single snapshot. |
|

|
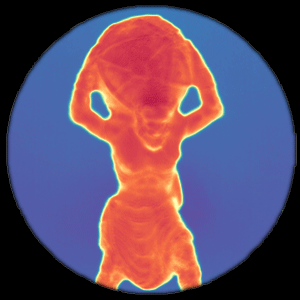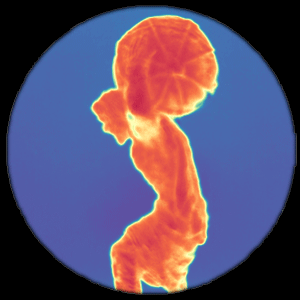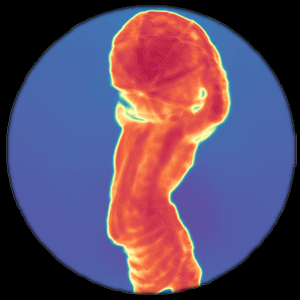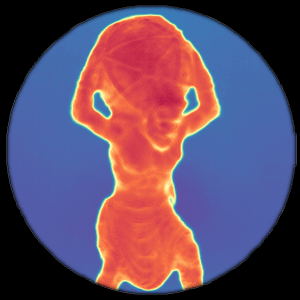
CVPR, 2021 Flying pixels are pervasive depth artifacts in time-of-flight imaging, formed by light paths from both an object and its background connecting to the same sensor pixel. Mask-ToF jointly learns a microlens-level occlusion mask and refinement network to respectively encode and decode geometric information in device measurements, helping reduce these artifacts while remaining light efficient. |
|
Flying pixels are pervasive depth artifacts in time-of-flight imaging, formed by light paths from both an object and its background connecting to the same sensor pixel. Mask-ToF jointly learns a microlens-level occlusion mask and refinement network to respectively encode and decode geometric information in device measurements, helping reduce these artifacts while remaining light efficient. |
|


|
Dominic Carrano, 6th International Conference on Higher Education Advances (HEAd), 2020 Jupyter Notebook labs can offer a similar experience to in-person lab sections while being self-contained, with relevant resources embedded in their cells. They interactively demonstrate real-life applications of signal processing while reducing overhead for course staff. |
|
Jupyter Notebook labs can offer a similar experience to in-person lab sections while being self-contained, with relevant resources embedded in their cells. They interactively demonstrate real-life applications of signal processing while reducing overhead for course staff. |
|
|
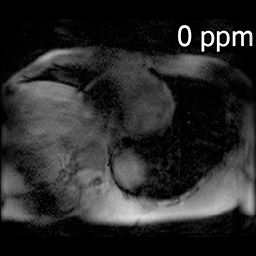
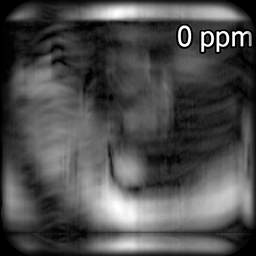
28th Annual Meeting of International Society for Magnetic Resonance in Medicine (ISMRM), 2020 Leveraging sparsity in the Z-spectrum domain, multi-scale low rank reconstruction of cardiac chemical exchange saturation transfer (CEST) MRI can allow for 4-fold acceleration of scans while providing accurate Lorentzian line-fit analysis. |
|
Leveraging sparsity in the Z-spectrum domain, multi-scale low rank reconstruction of cardiac chemical exchange saturation transfer (CEST) MRI can allow for 4-fold acceleration of scans while providing accurate Lorentzian line-fit analysis. |
|
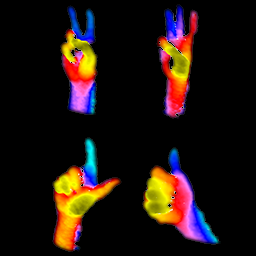
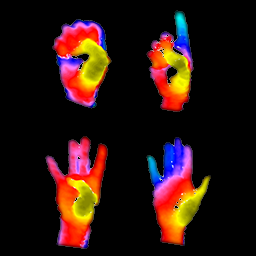
|
IEEE International Conference on Image Processing (ICIP), 2019 Point cloud data integrated from two structured light sensors for gesture recognition implicitly via a 3D spatial transform network can lead to improved results as compared to iterative closest point (ICP) registered point clouds. |
|
Point cloud data integrated from two structured light sensors for gesture recognition implicitly via a 3D spatial transform network can lead to improved results as compared to iterative closest point (ICP) registered point clouds. |
|
|
Website template stolen from
|